Quote:
Originally Posted by saint825xtc
That is super helpful Halvar. I appreciate it.
Do you have any ideas on how to pull the image files from these 2 sites. I couldn't find the source location of the images.
http://magzus.com/read/penthouse_let...pril_2017_usa/
This one has an option for "reading online" which opens up a frame and allows you to flip through the pages. |
Oh, these are fun. Not all of them work the same way, but this one can be cracked.
What you're going to want to do is to turn on the "Developer Tools" option (I'm using Firefox) and then take a look at the "GET" functions listed under "cached media" tab . . . you can see there the plain URL to the images. These tools in Firefox (there are similar ones in other browsers, they all work similarly) are incredibly powerful, they can let you watch as a particular webpage goes back to a server for graphics resources; since the aim of the designers is to make this hard to do, there are a lot of wrinkles.
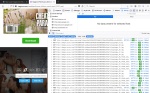
So that's what I'm seeing when I load that page, it may be hard to see, but I've selected the "Storage" tab-- its in blue because its selected-- so what I'm looking at are the "GET"s that this page is doing to store locally on my machine, which include the URLs of all the actual JPGs of pages in the magazine.
Notice that I've got the URLs to images, like this
Code:
http://image.issuu.com/170228092429-a44baae32e0c0ec0323085902a9faef1/jpg/page_17.jpg
and notice that the pattern
hXXp://image.issuu.com/170228092429-a44baae32e0c0ec0323085902a9faef1/jpg/page_ [somenumber.jpg]
is repeated for all the pages, so you can use a CURL loop as halvar illustrated above and grab all the pages, by iterating the [somenumber] from 1 to the highest page number
Copy and paste this into Terminal on a Mac (with CURL)
Code:
for x in $(seq 1 148); do curl -o $x.jpg http://image.issuu.com/170228092429-a44baae32e0c0ec0323085902a9faef1/jpg/page_$x.jpg; done